随着企业数据规模的指数级增长和业务复杂度的提升,传统集中式的数据架构逐渐暴露出瓶颈,如开发效率低下、数据治理困难、跨部门协作不畅等。为了应对这些挑战,一种新兴的架构范式——Data Mesh(数据网格)应运而生,它结合分布式领域驱动设计(DDD)的原则,为构建可扩展、敏捷且自治的数据处理服务提供了全新思路。本文将探讨基于Data Mesh构建分布式领域驱动架构的最佳实践,并聚焦于数据处理服务的核心要素和实施路径。
一、Data Mesh与领域驱动设计的核心理念融合
Data Mesh由ThoughtWorks的Zhamak Dehghani提出,其核心思想是将数据视为一种产品,并通过去中心化的领域所有权来管理数据。这与领域驱动设计中的“限界上下文”(Bounded Context)和“领域模型”高度契合。在分布式架构中,每个业务领域团队负责自己的数据处理服务,实现数据的自主管理和交付,从而打破数据孤岛,提升整体效率。
最佳实践建议:
- 识别领域边界:基于业务功能划分数据领域,例如用户数据、订单数据、库存数据等,每个领域对应一个独立的数据处理服务。
- 定义数据产品:将每个领域的数据封装为可复用的产品,明确数据的所有者、消费者和质量标准,确保数据的一致性和可靠性。
二、构建分布式数据处理服务的关键组件
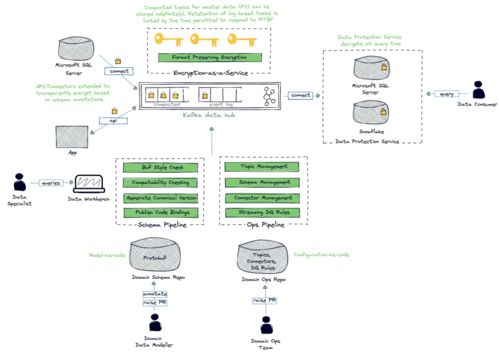
在Data Mesh架构中,数据处理服务是核心单元,它需要具备自治性、可发现性和互操作性。以下是最佳实践中的关键组件设计:
- 领域专属数据处理管道:每个领域团队应构建自己的数据处理流水线,包括数据摄入、清洗、转换和存储。使用轻量级工具(如Apache Kafka、Airflow)实现流水线自动化,减少对中央团队的依赖。
- 标准化接口与协议:通过API(如REST或GraphQL)暴露数据产品,确保跨领域的数据消费无需了解底层实现细节。采用通用数据格式(如Parquet、Avro)提升互操作性。
- 数据治理与质量监控:嵌入数据质量检查、元数据管理和访问控制机制。例如,使用数据目录(如Amundsen)实现数据的可发现性,并利用自动化测试保障数据质量。
三、实施路径与挑战应对
从传统架构迁移到Data Mesh需要循序渐进。最佳实践建议分阶段推进:
- 试点阶段:选择一个业务价值高、数据复杂度适中的领域作为试点,例如销售数据分析服务。团队需建立完整的数据产品生命周期,并验证技术栈的可行性。
- 扩展阶段:基于试点经验,逐步推广到其他领域。建立中心化的支持平台,提供共享工具(如数据编排引擎)和治理框架,以平衡自治与标准化。
- 文化转型:Data Mesh不仅是技术变革,更是组织文化的重塑。鼓励团队拥抱数据所有权,培养数据产品思维,并通过跨领域协作会议促进知识共享。
常见挑战包括技术债务积累、团队技能缺口和治理冲突。应对策略包括:投资自动化工具减少手动操作,提供培训提升数据工程能力,以及设立轻量级治理委员会协调跨领域决策。
四、案例启示与未来展望
以某电商平台为例,通过实施Data Mesh,其订单处理、用户推荐和库存管理等领域团队独立构建了数据处理服务。结果,数据交付时间缩短了60%,跨团队协作效率显著提升。随着AI和实时计算技术的发展,Data Mesh架构有望进一步融合事件驱动设计,实现更动态的数据处理能力。
基于Data Mesh构建分布式领域驱动架构,通过将数据责任下放至领域团队,能够有效提升数据处理服务的敏捷性和可扩展性。企业应从理念认同、技术选型和组织调整三方面入手,以渐进式实践迈向数据驱动的未来。